Load LoRA
🧠 What This Node Does
The Load LoRA node in ComfyUI is your go-to for injecting additional style, character, costume, or context into your image generation without retraining your base model. LoRA (Low-Rank Adaptation) models are lightweight, fine-tuned layers that can be dynamically applied to the base Stable Diffusion model at runtime. This node lets you load one and set how strong it should be — for both the model weights and the CLIP text encoder.
No more bloated model folders or checkpoint-switching gymnastics. With this node, you can stack, mix, and fine-tune LoRA styles like a digital alchemist.
🔧 Node Settings and Parameters (in painstaking detail)
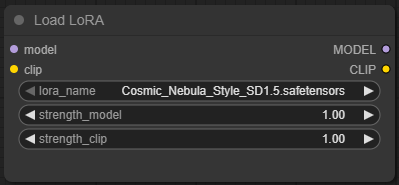
🔹 lora_name (Combo)
- Type: Dropdown list / file selector
- Purpose: Selects which LoRA
.safetensorsfile to load from your configuredComfyUI/models/loradirectory. - Required: Yes. Without this, you're doing nothing but wasting node real estate.
What it does: Loads the LoRA file so its learned weights can be applied to the MODEL and optionally to CLIP. You’ll only see LoRAs that are placed in your designated LoRA folder.
Tip: LoRAs often have naming conventions like style_v1.0.safetensors or outfit-swap-topV2.safetensors — pay attention to versions and suffixes if you’ve got a cluttered folder.
🔹 strength_model (Float)
- Type: Slider or manual input (usually 0.0 to 1.0, but technically can go higher)
- Default: 1.0
- Purpose: Controls how strongly the LoRA is applied to the model weights (the UNet).
What it does:
- At
1.0, you’re applying the LoRA exactly as it was trained. - At
<1.0, you're blending it partially, giving a subtler effect — useful if you want just a hint of style without overpowering your base model. - At
>1.0, you’re going into "LoRA overload" territory — which can create interesting or downright cursed images. Experiment with caution.
Why it's important: This controls how much of the visual representation of the LoRA gets expressed. Things like character identity, costume, pose influence, or scene lighting could be stronger or weaker depending on this setting.
🔹 strength_clip (Float)
- Type: Slider or manual input (usually 0.0 to 1.0, but like above, can go over)
- Default: 1.0
- Purpose: Controls how strongly the LoRA influences the CLIP text encoder.
What it does:
- At
1.0, the LoRA's textual association is fully applied to your prompt — so if the LoRA includes baked-in prompt logic (like turning "cyber dress" into a whole aesthetic), it'll show up strongly. - At
<1.0, the LoRA has a weaker impact on prompt interpretation. Great for when you're blending multiple concepts and don't want your LoRA throwing elbows. - At
0.0, you’re disabling the CLIP influence completely — only the model side gets LoRA-weighted. This can be useful when your prompt does enough heavy lifting on its own.
Why it matters: Many LoRAs rely on CLIP alignment to interpret prompts the way the LoRA creator intended. If you skip or weaken CLIP influence, you might get unexpected or diluted results.
🧩 Inputs & Outputs
🔸 Inputs
- None. This is a self-contained loader node. It doesn’t need model inputs because it’s responsible for loading the LoRA and outputting it for use downstream.
🔸 Outputs
MODEL: LoRA-loaded model layer (for use in the KSampler or similar).CLIP: LoRA-loaded CLIP layer (for use wherever text encoding is needed).
These outputs are typically routed into a KSampler or chained into other model composition nodes.
⚙️ Workflow Setup Example
Here’s a simple LoRA-enabled text-to-image workflow setup:
[Checkpoint Loader] → [Load LoRA] → [KSampler] ↓ [Positive/Negative Prompt]
Steps:
- Load your base checkpoint (e.g.,
dreamshaper_8.safetensors). - Load a LoRA (e.g.,
flowing-fabrics.safetensors) with appropriate strength values. - Connect the outputs of both nodes into your
KSampler. - Profit (artistically speaking).
🎯 Recommended Use Cases
- ✨ Character LoRAs: Inject specific character traits (like "Gwen Stacy" or "Cyberpunk Girl") into your generation without a bloated 8GB model.
- 👗 Outfit/Style LoRAs: Add a tank top, medieval armor, or ethereal dress — yes, there are LoRAs for all of these.
- 🏞️ Scene/Lighting LoRAs: Apply cinematic tones, color grading, or fantasy lighting with subtle strength blending.
- 🔀 Multi-LoRA Blends: Load multiple
Load LoRAnodes with different strengths and mix aesthetics.
💡 Prompting Tips
- Always use the trigger word if the LoRA author requires it. You can often find this on CivitAI or in the LoRA’s documentation.
- Adjust
strength_modelvsstrength_clipindependently to create dynamic effects — e.g., strong visual style but loose textual interpretation. - Stack LoRAs with different strengths to layer concepts — just don’t go full mad scientist unless you enjoy chaos.
🚫 What-Not-To-Do-Unless-You-Want-a-Fire
Or: How to summon an eldritch horror from your LoRA folder by accident.
❌ Crank strength_model to 10
Unless you’re trying to create an abomination that looks like it fell through an AI meat grinder, keep your strength_model values under control. Values over 1.5 often lead to overbaked noise, facial meltdowns, and what I like to call "LoRA hallucinations." Basically: you told the model to do too much and it panicked.
❌ Set strength_clip to 0 without knowing what it does
This disables the CLIP side of the LoRA — which might be what you want... unless the LoRA relies on textual influence to work correctly. A LoRA for "goth bunny assassin" might just look like a blurry mess without the CLIP component helping the model interpret your prompt.
❌ Forget to use the LoRA’s trigger word
Many LoRAs require specific activation keywords to function (e.g., cyberdress, tanktop, angelcore_v1). If your prompt doesn't contain the trigger, the LoRA might just sit there doing nothing, judging you silently.
❌ Mix LoRAs that were never meant to be mixed
You can load multiple LoRAs, but stacking "realistic portrait v2," "anime body horror v9," and "pixel art cave troll" might just cause a visual nervous breakdown. Unless you're doing this for the memes, avoid wildly incompatible styles.
❌ Load an SDXL LoRA into an SD1.5 workflow
It won’t work. It shouldn't even load properly — but if you force it with dark magic or manual renaming, expect nothing but digital static. LoRAs are trained for specific base models. Cross-version contamination is a fast track to wasted time and terrifying outputs.
❌ Use high-strength LoRA with highly detailed conflicting prompts
Prompts like "hyper-realistic woman in a power suit, cinematic lighting, gothic castle" combined with a LoRA that adds "manga catgirl swimsuit beachcore" at strength_model=1.2 is... asking for an identity crisis. Don’t expect harmony from chaos.
❌ Forget to match your LoRA’s style with the right base checkpoint
A stylized LoRA meant for revAnimated_v122 won’t look right when paired with deliberate_v11 or dreamshaper_8 if their base styles conflict. If you’re using a LoRA that was clearly made for a cartoony model, don’t slap it onto a realism checkpoint unless you’re fine with the Uncanny Valley getting a new zip code.
❌ Assume LoRA = Insta-Magic
LoRAs enhance generation — they don’t override bad prompts, broken seeds, or mismatched models. If your base setup is junk, the LoRA won’t save you. It’ll just add stylish failure.
Keep it sane. Keep it smooth. Respect the LoRA. Or do all of the above and start your own AI horror gallery — your call.
🧪 Advanced Nerd Stuff (Optional but Cool)
- You can technically swap LoRA files mid-workflow using
LoRA Stacklogic or automation — but that’s for more advanced setups. - Some users use math nodes to dynamically control
strength_modelandstrength_clipfor evolving animations or staged variations.
🧼 Final Thoughts
The Load LoRA node is one of the most powerful and underappreciated nodes in ComfyUI. It gives you the ability to radically transform your outputs without needing to bake in permanent changes to your checkpoint. Use it wisely — or go full chaos gremlin and push it to 2.5 for memes. Either way, experiment, break things, and enjoy the ride.